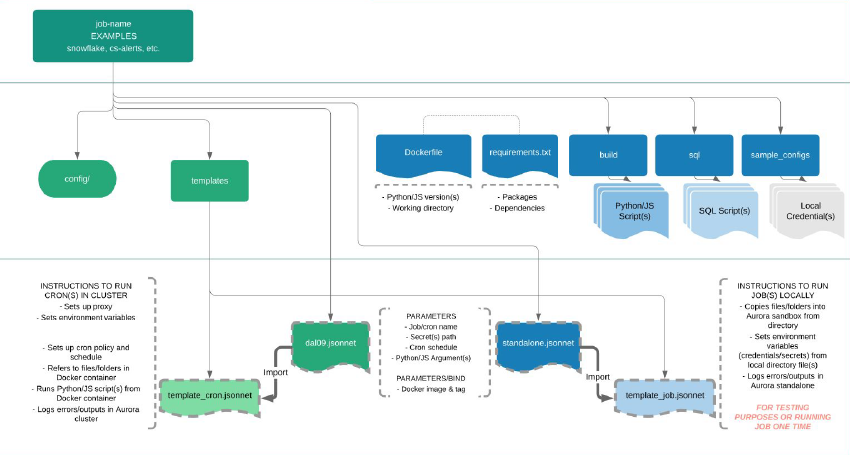
Appropriately allocating resources for distributed system job automation can be a key responsibility of any data team, especially if the data landscape and scope is large. If resources are constrained, it is increasingly important to understand and communicate tradeoffs between fresh data and highly performant data visualizations. Creating a versatile set of templates that can accommodate various types of automation jobs is key to minimizing time wasted unnecessarily recoding. During a three month period of time, I calibrated and templated Python, Jsonnet, Javascript, and other files using the Apache Aurora Mesos framework. From the templates, I automated dozens of data refresh cron jobs including ETL of real-time data from third-party APIs, Google Drive and Dropbox flat file ETL into a data warehouse, and refreshing denormalized data tables.

You must be logged in to post a comment.